
Advertise here via BSA
Today's front-end developers don't just need to understand how to write CSS, we need to know how to write it efficiently. And what "efficiently" means can depend on your project and environment. Perhaps you have a team with several members working in the CSS and you need an efficient way to work together. Or maybe you have a huge enterprise site and you need your CSS optimized for speed. You could even be working with a legacy system that restricts access to HTML, which means you need efficient selectors to effectively style elements without ids or classes. You might even face all these situations and more.
Whatever your goals for CSS are, the best way to reach them is to know your options, and that means understanding all the selectors available to you. Most of us are already familiar with id and class selectors, and I introduced you to the beauty of attribute selectors in "Understanding CSS Selectors." But there's so much more.

In this two-part series, I'll look at the new selectors in CSS3, starting with structural pseudo-classes.
What's a Pseudo-Class?
CSS pseudo-classes target elements that can't be targeted with combinators or simple selectors like id or class. You use pseudo-classes to select elements based on their attributes, states, and relative position. For example, you are probably already familiar with pseudo-classes for link states:
:link
:visited
:hover
:active
:focus
CSS3 introduces a number of new pseudo-classes, including structural pseudo-classes that target elements according to their position in the document tree and relation to other elements. Here's a list of the structural pseudo-classes you'll see examples of in this article.
:root
: only-child
:empty
:nth-child(n)
:nth-last-child(n)
:first-of-type
:last-of-type
: only-of-type
:nth-of-type(n)
:nth-last-of-type(n)
:first-child
:last-child
Before we look at the details, let's touch briefly on the syntax you use with pseudo-classes.
Pseudo-Class Syntax
The syntax for pseudo-classes uses a colon (:) followed by the pseudo-class name:
:pseudo-class {}
If you want to target a specific element (e), you append that element to the beginning of the pseudo-class syntax:
e:pseudo-class {}
You can even use pseudo-classes alongside id and class selectors, as you see here:
#id:pseudo-class {}
.class:pseudo-class {}
Numeric Values
Some of the CSS3 pseudo-classes target elements on the basis of the elements' specific location in the document tree. You indicate the position with a numeric value in parenthesis (n) appended to the pseudo-class name:
:pseudo-class(n) {}
The value of (n) can be an integer to indicate an element's position in the document tree. The following example targets the third element that meets the pseudo-class rule:
:pseudo-class(3) {}
You can also specify numeric formulas, such as "every fifth element," which is indicated as a value of (5n):
:pseudo-class(5n) {}
Additionally, you can specify an offset formula (negative values allowed; default is zero) by adding (+) or subtracting (-) the offset value:
:pseudo-class(5n+1) {}
These new selectors also allow you to target elements by their document tree order with the keywords odd and even. For example, if you want to target the odd-numbered elements, use the following:
:pseudo-class(odd) {}
Putting Pseudo-Classes to Work
Now that you've seen the general syntax, let's look at some of the new selectors in more detail and see examples of the style effects you can achieve by using them.
:root
The :root pseudo-class targets the root element—the html element. Consider the following basic markup for a page:
<!DOCTYPE html> <head> <title>Getting to Know CSS3 Selectors</title> </head> <body> </body> </html>
If you want to apply a main background color to this page, with a different background color to show a "container," you could do this with CSS only and no new markup, as shown here:
:root{ background-color: rgb(56,41,48); } body { background-color: rgba(255, 255, 255, .9); margin: 0 auto; min-height: 350px; width: 700px; } In this example, I applied the background color to the html element via :root and applied the styles for the container via a type selector for body. This results in the simple visual layout shown in Figure 1.

Figure 1 An example of a page with a dark background color assigned to the root html element and a lighter background color assigned to the body element.
: only-child
The : only-child pseudo-class targets an element that is the only child of its parent. That means the parent element contains only one other element. The : only-child pseudo-class is different from the :root pseudo-class, which assumes the html element. You can use : only-child to target any element by appending the pseudo-class syntax to the element (e), like this:
e: only-child {}
For example, perhaps you have a block of text in which you promote a new item:
<h2><b>Available Now!</b> Paperback edition of The Zombie Survival Guide: Complete Protection from the Living Dead</h2>
If you want to style the text "Available Now" as a callout, you could use : only-child to target the b element, which is the only child of the h2. Figure 2 shows the code you would use.
h2 { background: rgb(255, 255, 255) url(zombies.png) no-repeat 97% 4%; border: 1px solid rgba(125, 104, 99, .3); border-radius: 10px; color: rgb(125,104,99); font: normal 20px Georgia, "Times New Roman", Times, serif; padding: 20px 20px 20px 60px; position: relative; width: 450px; } b:only-child { background-color: rgb(156,41,48); color: rgb(255,255,255); display: block; font: bold 12px Arial, Helvetica, sans-serif; font-weight: bold; letter-spacing: 1px; padding: 10px; text-align: center; text-transform: uppercase; -moz-transform: translate(-70px) rotate(-5deg) matrix(1, -0.2, 0, 1, 0, 0); -moz-transform-origin: 50px 0; -webkit-transform: translate(-70px) rotate(-5deg) matrix(1, -0.2, 0, 1, 0, 0); -webkit-transform-origin: 50px 0; -o-transform: translate(-70px) rotate(-5deg) matrix(1, -0.2, 0, 1, 0, 0); -o-transform-origin: 50px 0; -ms-transform: translate(-70px) rotate(-5deg) matrix(1, -0.2, 0, 1, 0, 0); -ms-transform-origin: 50px 0; transform: translate(-30px) rotate(-5deg) matrix(1, -0.2, 0, 1, 0, 0); transform-origin: 50px 0 0; width: 150px; } Figure 2 Use the : only-child pseudo-class to callout and emphasize text within a heading.
This CSS results in the visual callout seen in Figure 3, which doesn't need any id or class attributes added to the HTML.

Figure 3 An example of a callout for a product promotion.
:empty
The :empty pseudo-class targets elements that don't have any children or any text—an empty element such as:
<p></p>
Personally, I can't think of a situation when I would allow an empty element to be rendered on a site, but that doesn't mean there isn't an edge case. In terms of syntax, you could target every empty element with the pseudo-class on its own:
:empty { background-color: red; } Or, as in the example of the : only-child pseudo-class, you can target a specific element, like td:
td:empty { background-color: red; } :nth-child(n)
This is the first pseudo-class I'm covering that takes advantage of the numeric values described earlier. The :nth-child pseudo-class targets a child element in relation to its position within the parent element. A list of blog comments, for example, might look nice with alternating background colors, as in Figure 4.
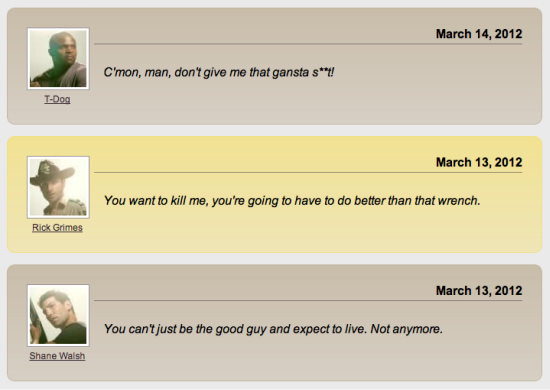
Figure 4 An example of a list of blog post comments with alternating styles
The HTML for this example is just an ordered list, as shown in Figure 5.
<ol> <li> <p>March 14, 2012</p> <a href="http://nocommonsense.com"><img src="tdog.jpg" alt="T-Dog" /></a> <p><a href="http://nocommonsense.com">T-Dog</a></p> <p>C'mon, man, don't give me that gansta s**t!</p> </li> <li> <p>March 13, 2012</p> <a href="http://itsallblackandwhite.com"><img src="rickgrimes.jpg" alt="Rick Grimes" /></a> <p><a href="http://itsallblackandwhite.com">Rick Grimes</a></p> <p>You want to kill me, you're going to have to do better than that wrench.</p> </li> <li> <p>March 13, 2012</p> <a href="http://becameawalker.com"><img src="shanewalsh.jpg" alt="Shane Walsh" /></a> <p><a href="http://becameawalker.com">Shane Walsh</a></p> <p>You can't just be the good guy and expect to live. Not anymore.</p> </li> </ol>
Figure 5 The HTML for the blog post example.
To style this markup, I first target the list items with a simple type selector, as shown in Figure 6:
li { background-color: rgba(194, 181, 158, .5); background-image: -webkit-gradient(linear, left top, left bottom, from(rgba(194, 181, 158, .7)), to(rgba(194, 181, 158, 0))); background-image: -moz-linear-gradient(top, rgba(194, 181, 158, .7), rgba(194, 181, 158, 0)); background-image: -o-linear-gradient( rgba(194, 181, 158, .7), rgba(194, 181, 158, 0)); border: 1px solid rgb(194, 181, 158); border-radius: 10px; margin: 15px 0; padding: 25px; } Figure 6 Styles for the blog post example.
Then, using the :nth-child() pseudo-class, I target the even-numbered list items:
li:nth-child(even){ background-color: rgba(242, 224, 131, .5); background-image: -webkit-gradient(linear, left top, left bottom, from(rgba(242, 224, 131, .7)), to(rgba(242, 224, 131, 0))); background-image: -moz-linear-gradient(top, rgba(242, 224, 131, .7), rgba(242, 224, 131, 0)); background-image: -o-linear-gradient( rgba(242, 224, 131, .7), rgba(242,224, 131, 0)); border: 1px solid rgb(242, 224, 131); } :nth-last-child(n)
The :nth-last-child(n) pseudo-class works just like :nth-child(n), except the order is determined in relation to the last child element, rather than the first. Using the same blog comments example, consider the content within each list item:
<li> <p>March 14, 2012</p> <a href="http://nocommonsense.com"><img src="tdog.jpg" alt="T-Dog" /></a> <p><a href="http://nocommonsense.com">T-Dog</a></p> <p>C'mon, man, don't give me that gansta s**t!</p> </li>
Each of the paragraph elements that comprise the comment need to be uniquely styled, as does the image. (See Figure 7).

Figure 7 This blog comment features different styles for the different types of content within it
For the commenter name and link, I use the :nth-last-child(n) pseudo-class with a numeric value to target the second-to-last paragraph within the list item:
p:nth-last-child(2) { clear: left; float: left; font-size: 12px; margin-top: 5px; text-align: center; width: 80px; } :first-of-type
The :first-of-type pseudo-class targets the first of a specific type of element within a parent. In the blog comment example, I can target the date content as the first paragraph within the list item:
<li> <p>March 14, 2012</p> <a href="http://nocommonsense.com"><img src="tdog.jpg" alt="T-Dog" /></a> <p><a href="http://nocommonsense.com">T-Dog</a></p> <p>C'mon, man, don't give me that gansta s**t!</p> </li>
Using :first-of-type, I style the first paragraph (containing the date) to be right-justified with a bottom border:
p:first-of-type { border-bottom: 1px solid rgba(56,41,48, .5); float: right; font-weight: bold; padding-bottom: 3px; text-align: right; width: 560px; } :last-of-type
The :last-of-type pseudo-class targets just what the name says: the last element type within a parent. In the blog example, I can style the comment text in the last paragraph like this:
<li> <p>March 14, 2012</p> <a href="http://nocommonsense.com"><img src="tdog.jpg" alt="T-Dog" /></a> <p><a href="http://nocommonsense.com">T-Dog</a></p> <p>C'mon, man, don't give me that gansta s**t!</p> </li>
In Figure 7 you can see how I used :last-of-type to style the last paragraph. Here is the CSS I used:
p:last-of-type { font-style: italic; margin: 50px 10px 10px 100px; } : only-of-type
The : only-of-type pseudo-class targets a child element that is the only one of its type within the parent element. Continuing with the blog comment example, you can use this selector to target the avatar:
<li> <p>March 14, 2012</p> <a href="http://nocommonsense.com"><img src="tdog.jpg" alt="T-Dog" /></a> <p><a href="http://nocommonsense.com">T-Dog</a></p> <p>C'mon, man, don't give me that gansta s**t!</p> </li>
CSS:
img:only-of-type{ background-color: rgb(255, 255,255); border: 1px solid rgba(56,41,48, .5); float: left; padding: 3px; } :nth-of-type(n)
The :nth-of-type(n) pseudo-class works similarly to the other numeric-based pseudo-classes I've covered. This pseudo-class targets a specific element type according to its position relative to the parent element. You can see an example of the effects you can achieve in the simple shopping cart view shown in Figure 8.

Figure 8 A shopping cart view that features unique styles for different table cells
The HTML for this cart, listed in Figure 9, is in a table. (Remember that tables are fine for data but please avoid them for layout).
<table cellspacing="0"> <tr> <th>Quanity</th> <th>Item</th> <th>Price</th> </tr> <tr> <td>1</td> <td>The Zombie Survival Guide: Complete Protection from the Living Dead</td> <td>$13.95</td> </tr> <tr> <td>1</td> <td>Gerber Apocalypse Kit</td> <td>$349.00</td> </tr> <tr> <td>1</td> <td>Kookaburra BIG Kahuna 2010 Cricket Bat</td> <td>$189.95</td> </tr> <tr> <td>1</td> <td>40" Samurai Sword</td> <td>$159.00</td> </tr>
Figure 9 The HTML for the shopping cart.
To style several of these table elements, I use the :nth-of-type(n) selector to style the text alignment of the table header and data cells. For example, the Item table header cell needs to be aligned left (the default is centered).
<tr> <th>Quanity</th> <th>Item</th> <th>Price</th> </tr>
With the :nth-of-type(n) selector, you can target that specific child:
th:nth-of-type(2) { text-align: left; } I can use the same pseudo-class to style the remaining text alignment needed, without a single class or id:
th:nth-of-type(3), td:nth-of-type(3) { text-align: right; } th:nth-of-type(1), td:nth-of-type(1) { text-align: center; } :nth-last-of-type(n)
The :nth-last-of-type(n) pseudo-class works just like :nth-of-type(n), but the relative position is offset from the last child rather than the first. In the shopping cart example, the Subtotal, Tax, Shipping and Total rows need unique styles, as shown in Figure 10.

Figure 10 Unique styles for the subtotal, total and other rows
Let's look at the Subtotal row, which is the fourth row (tr) from the bottom in the table:
<tr> <td colspan="2">Subtotal</td> <td>$711.19</td> </tr>
I used :nth-last-of-type(n) to give this row of cells the style seen in the figure. This is the CSS I used:
tr:nth-last-of-type(4) td { border-top: 1px solid rgb(56,41,48); font-style: italic; font-weight: bold; text-align: right; } And I continued with this pseudo-class for the remaining rows of the table:
tr:nth-last-of-type(1) td { background-color: rgb(56,41,48); color: rgb(255, 255, 255); font-size: 14px; font-style: italic; font-weight: bold; padding: 5px 10px; text-align:right; } tr:nth-last-of-type(2) td, tr:nth-last-of-type(3) td { font-style: italic; text-align: right; } :first-child
The :first-child pseudo-class targets the first child element, regardless of type, in a parent element. For this example, let's consider a sidebar that has a series of content elements (Figure 11).

Figure 11 A sidebar with different content sections
The markup I used for this example is a containing div, with nested aside elements, which is shown in Figure 12.
<div role="complementary"> <aside> <ul> <li><a href="http://youtube.com/whenzombiesattack">Subscribe to our YouTube channel</a></li> <li><a href="http://twitter.com/whenzombiesattack">Follow us on Twitter</a></li> <li><a href="http://facebook.com/whenzombiesattack">Like us on Facebook</a></li> </ul> </aside> <aside> <h3>Newsletter Sign-Up</h3> <p>The voodoo sacerdos flesh eater, suscitat mortuos comedere carnem virus.</p> <p><a href="http://www.webappers.com/newsletter/">Sign up now</a></p> </aside> <aside> <h3>From the Blog</h3> <p>Zombie ipsum reversus ab viral inferno, nam rick grimes malum cerebro. De carne lumbering animata corpora quaeritis. Summus brains sit, morbo vel maleficia? De apocalypsi gorger omero undead survivor dictum mauris.</p> <p><a href="/blog/">Read more</a></p> </aside> </div>
Figure 12 Markup for the sidebar
As you can see in Figure 11, the sidebar contains sections of content that have a defined border and background:
aside { background-color: rgb(255, 255, 255); border: 1px solid rgba(125, 104, 99, .5); border-radius: 10px; -moz-box-shadow: inset 0 0 20px rgba(125, 104, 99, .5); -webkit-box-shadow: inset 0 0 20px rgba(125, 104, 99, .5); box-shadow: inset 0 0 20px rgba(125, 104, 99, .5); margin-bottom: 20px; padding: 25px; } However, the first aside contains social media icons and lacks a border and background (see the top of Figure 11). I used the :first-child pseudo-class to target this first section of content:
aside:first-child { background-color: transparent; border: 0; -moz-box-shadow: none; -webkit-box-shadow: none; box-shadow: none; padding: 0; } :last-child
The :last-child pseudo-class is the opposite of :first-child, targeting the last child element within a parent. Going back to the sidebar example shown in Figure 11, the first section contains a list (ul) of social media links:
<ul> <li><a href="http://youtube.com/whenzombiesattack">Subscribe to our YouTube channel</a></li> <li><a href="http://twitter.com/whenzombiesattack">Follow us on Twitter</a></li> <li><a href="http://facebook.com/whenzombiesattack">Like us on Facebook</a></li> </ul>
Each of these links is rendered on the screen as a different icon, achieved with a simple image-replacement technique and sprites:
li a { background: url(Sprites.png) no-repeat 2px 7px; display:block; height: 64px; text-indent: -5000px; width: 64px; } In order to style the last link in the list, I use the :last-child pseudo-class:
li:last-child a { background-position: -100px 7px; } The remaining middle link is styled with the :nth-child() pseudo-class:
li:nth-child(2) a { background-position: -200px 7px; } Browser Support
The good news is that all the latest browser versions, including Internet Explorer 10 and 9, support these CSS3 pseudo-classes. Some older browser versions may provide limited support for a few of the CSS3 selectors in this article.
When it comes to support in earlier version of Internet Explorer, it really should be about your project. How are you using any unsupported selectors? If it is purely for design and aesthetic purposes, ask yourself whether you can allow those Internet Explorer users to have a slightly degraded experience, while allowing Internet Explorer 9 and other browser users to have an enhanced experience. If the answer is yes, consider focusing on an adaptive approach to your CSS.
If you need earlier versions of Internet Explorer to support your CSS3 pseudo-classes, check out Selectivzr, a JS utility that emulates CSS3 pseudo-class support in Internet Explorer. It works with jQuery, Dojo, MooTools and Prototype.
Processing
The (sorta) bad news about browsers and CSS3 pseudo-classes is that in terms of how efficiently browsers process selectors, pseudo-classes fall to the bottom of the list. If performance and speed are paramount for your project, you should use pseudo-classes judiciously. I recommend taking advantage of some testing tools to help you best optimize your CSS selectors. Some good ones are:
CSS Test Creator
CSSLint
Knowing When and What to Use
So how do you decide which selectors to use? The answer depends on your project. Knowing both your project and the CSS selectors available will help you decide. The CSS3 pseudo-classes I covered in this article may not be the "bread and butter" selectors for your stylesheets, but they can be invaluable tools, particularly for cases when you can't rely on id and class selectors. Remember, writing good CSS is about finding the most efficient way to achieve a project's goals.
Stay Tuned!
Keep your eye out for Part 2 of "CSS3 Selectors: Structural Pseudo-Classes" In that article, I'll cover UI element state pseudo-classes as well as the :target and negation pseudo-classes.
About the Author
Emily Lewis is a freelance web designer of the standardista variety, which means she gets geeky about things like semantic markup andCSS, usability and accessibility. As part of her ongoing quest to spread the good word about standards, she writes about web design on her blog, A Blog Not Limited, and is the author of Microformats Made Simple and a contributing author for the HTML5 Cookbook. She's also a guest writer for Web Standards Sherpa, .net magazine and MIX Online.
In addition to loving all things web, Emily is passionate about community building and knowledge sharing. She co-founded and co-manages Webuquerque, the New Mexico Adobe User Group for Web Professionals, and is a co-host of the The ExpressionEngine Podcast. Emily also speaks at conferences and events all over the country, including SXSW, MIX, In Control, Voices That Matter, New Mexico Technology Council, InterLab and the University of New Mexico.
Sponsors
Professional Web Icons for Your Websites and Applications













